Time is a tricky concept. When we happy it flies fast, when we wait for something and have nothing to do it goes painfully slow but intuitively we believe it's absolute and its rate is constant.
Physicists abandoned the idea of absolute time at the beginning of XX century and the theories of relativity state that it indeed may go faster or slower for different observers (clocks). Besides that, the theory sets the limit on the speed of signal propagation. So it takes time to sync clocks and hence they can't be perfectly in sync.
The reason why we hadn't noticed this strangeness earlier is because the distortion of time is too small compared to the pace of our life.
But computers changed the speed of information processing so we, software engineers, start to experience the problems, physicists had for the last century.
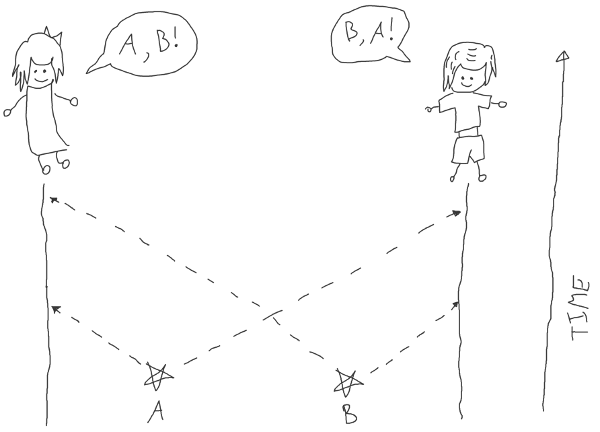
When an execution of a program limited by one computer the local timer plays a role of absolute clock and we can use our intuitive perception of time to reason about the behavior. But when a program is distributed we enter the relativity domain and must think like physicists. It may seem like an exaggeration but it very easy to run into time anomalies:
- World is big and information about local event reaches the other end of Earth in about 100ms so for different observers it happens at a different time even if their clocks are perfectly in sync.
- Different computers may have different time because of misconfiguration.
- NTP's accuracy is tens of milliseconds.
- Time may freeze during live migration caused by security update of yours cloud provider.
- Heat causes frequency drift and changes the speed of timer.
There are several techniques for dealing with time in distributed systems. In this post, I focus on timestamp oracle (TSO).
TSO, in its essence, is just a clock-like service exposing now() method - to get current "timestamp".
Let's pretend that absolute time exists and use our intuition to write spec:
now()must return a unique valuenow()returns a value between the moment it was invoked and the moment it returned the result
Now rewrite replacing absolute time with the happened-before relation - each invocation must yield a unique value and if one invocation finished before another started then the former must yield lesser value.
The simplest implementation of TSO is a counter in a database, a fault-tolerant performant implementation is a completely different beast.
But before jumping into different design of TSO, do we really need it?
Usage of the consensus based TSO in Percolator transaction protocol
TSO is a keystone of the Percolator transaction protocol described in the Large-scale Incremental Processing Using Distributed Transactions and Notifications paper. To my knowledge, it's the only distributed transaction protocol providing snapshot isolation. 2PC provides serializable and RAMP - read committed isolation levels.
For example, Percolator is used by the TiDB distributed database. Let's see what authors of TiDB and Google write about thier experience.
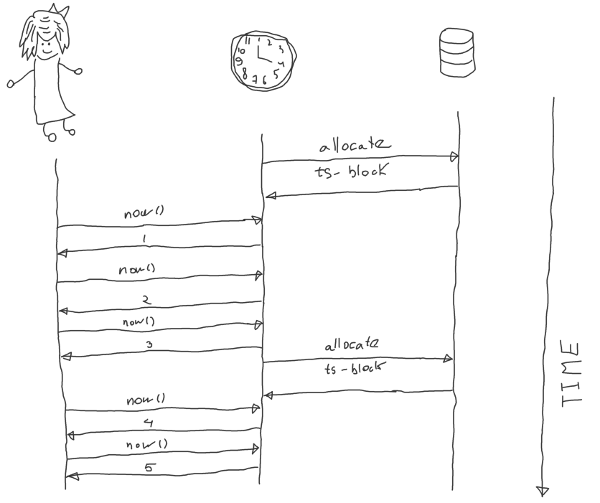
"Since every transaction requires contacting the timestamp oracle twice, this service must scale well. The oracle periodically allocates a range of timestamps by writing the highest allocated timestamp to stable storage; given an allocated range of timestamps, the oracle can satisfy future requests strictly from memory. If the oracle restarts, the timestamps will jump forward to the maximum allocated timestamp (but will never go backwards)" source
"The functions of TSO are provided in PD in TiKV. The generation of TSO in PD is purely memory operations and stores the TSO information in etcd on a regular base to ensure that TSO is still monotonic increasing even after PD restarts." source
Both systems allocate a range of timestamps from a replicated storage and serve requests from memory to minimize response time.
Obviously we can't have multiple TSO - if we have two TSO: A and B, and A allocated [0,100) and B allocated [100, 200) then when a client requests time from B and then from A she gets lesser value violating the spec. As a consequence, we can't immediately start new TSO when previous failed. If it's a network glitch then the old TSO may be still active and serving requests so we'll double TSO and a possibility of a violation.
Leases solve the problem: active TSO should ping replicated storage every n seconds and step down if ping doesn't pass and new TSO should wait at least for n seconds before starting serving requests in this case everything is fine. But leases have downsides:
- Implicit coupling via time.
- Dependency on the speed of local time which may fluctuate e.g. during the live migrations
Even if we close our eyes on them we should be accountable for the tradeoff we did - we traded availability during an incident for the latency of the happy case. Sometimes short violations of availability during the incidents are acceptable sometimes aren't but anyway we don't get improved latency for free.
Personally, as an engineer who is on call rotation, I'd prefer to work with a system which is robust during a disaster. Also it's really hard to think about a combosition of nondeterministic system, hard not like in "A hard day's night" but hard like hardly possible. It's easy to imagine when a minor glitch causes 1% of downtime in the A and B systems but 10% of downtime when the systems are combined.
Let's explore if we can design TSO without violating availability when a minor number of nodes are partitioned away.
Quorum clock
The straightforward idea is to go to a replicated storage on every request instead of using the cached range.
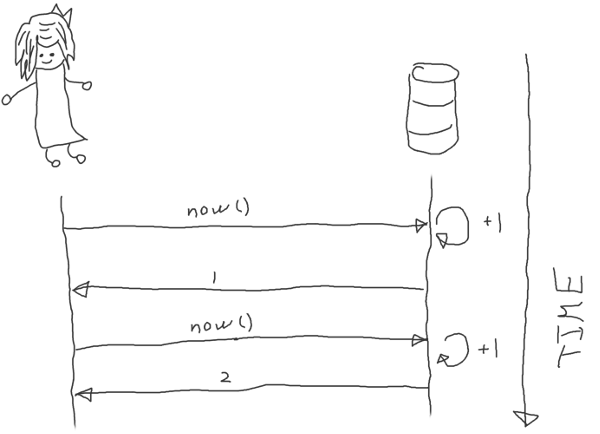
But it suffers from the same problem. There are several designs of replicated storage, some are based on the idea of the stable leader and are subject to availability loss during re-election. No, it isn't another rant on leader-based consensus. Leaderless variants are also affected: the time (clock) requires only one register and a leader-equivalent is needed to reduce contention - if it fails we still are in the same situation.
Instead of relying on consensus we go earlier in history and use an adaptation of Lamport clocks.
Lamport clock is a technique to track dependencies and assign "timestamps" to every event in a system such that if two events are causally related then the earlier has a lesser timestamp. LC doesn't provide uniqueness and out of two unrelated events, the one which happened earlier in absolute time may have a greater timestamp.
We'll iterate the idea and turn LC into TSO.
Probably the idea has been described before but I haven't seen it so let's name it Quorum Clock. If you know it under another name, please write in the comments.
Quorum Clock implements fault-tolerant TSO. The system consists of M time watching stateless nodes (TW), 2N+1 clock storage nodes (CS) and it's able to tolerate M-1 failures of TW nodes and N failures of CS nodes.
Each time watcher node has a unique id and it's used as a part of the timestamp. Actually, a timestamp is a tuple of stored time and TW's id.
How to generate timestamp?
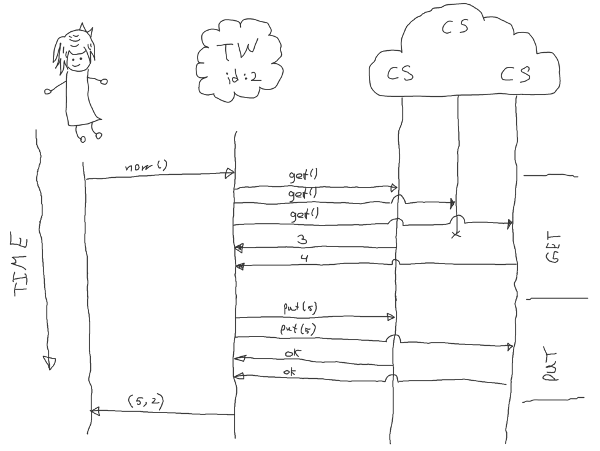
- Client randomly selects TW node and asks it for a timestamp.
- TW node asks CS nodes for their stored time.
- TW node waits for at least
N+1responses. - TW node picks maximum among responses, increment by one and sends it back to CS nodes.
- CS nodes overwrite the current value (if new is greater) and send a confirmation to the TW node.
- TW node waits for
N+1responses, creates (new stored time, TW's id) pair and passes it to the client.
When a client wants to compare two timestamps she compares the stored time and if they are equal uses TW's id as a tiebreaker.
Why does it work?
- If one request starts after another finish then there is at least one common CS and later request gets higher stored time by definition.
- If two requests are concurrent then it doesn't matter which one is earlier and unique TW's id guarantees uniqueness stored time components match.
Optimizations
If every client has a unique id then clients can play a role of TW nodes and reduce the number of hops by 1 RRT.
Another optimization is to serve requests to CS from RAM. We suppose that CS keeps time in a persistent memory (disk) and updates it on every put. But persistent memory is slow compared to RAM. Let's update the protocol to serve from RAM in most cases. To do it we should:
- Split CS's time into epoch and time.
- Keep epoch persisted on disk and time in RAM (zero when CS node starts).
- Increments epoch by one and persist it when CS starts.
- If put epoch is greater than current epoch overwrite current epoch on disk.
- Update time only in RAM.
Conclusion
It seems we came up a protocol of leaderless clock. Let's compare it to a consensus based solution:
- Same number or hops. Consensus counter: client → leader → acceptors → leader → client, quorum clock: client → CS → client → CS → client.
- When a leader is partitioned away consensus counter suffers from a short period of unavailability. Quorum clock tolerated isolation of any node without downtime.
- Quorum clock serves requests from memory without touching the disc.
Both solutions don't give the sense of time to an operator, making it hard to correlate real-world events with the behavior of the system. Hopefully hybrid logical clock has the same properties as Lamport clock but also include physical time in the timestamp so we can build quorum clock on top of HLC to overcome the correlation issue.